Laboratorium 0 #
Środowisko programistyczne #
Zanim przejdziemy do właściwej treści, musimy wybrać edytor, w którym będziemy pisali kod. W poprzednim semestrze było to Visual Studio. Nie ma ono swojej wersji na Linuxa (wielu programistów powiedziałoby: i bardzo dobrze, nie chcemy go). W naszym laboratorium dostępne jest:
- Visual Studio Code – niemające wiele wspólnego z Visual Studio środowisko (też wydawane przez Microsoft). Ma mniejszą funkcjonalność, ale dzięki temu jest znacznie szybsze i lżejsze.
- CLion – cięższe środowisko mające bardziej rozbudowaną funkcjonalność, bardziej przypominające Visual Studio.
- Vim – edytor tekstowy w terminalu. Bez odpowiedniej konfiguracji korzystanie z niego byłoby bardzo nieprzyjemne. Wbrew pozorom pozwala jednak na bardzo wiele rozszerzeń. Możliwości rozbudowy są jednak znacznie większe, niż w wymienionych wyżej edytorach.
- Emacs – edytor tekstowy, który podobnie jak vim, pozwala na dowolne rozbudowywanie funkcjonalności.
- Geany – prosty edytor tekstowy, bez wielkich możliwości rozbudowy.
Wybór środowiska zależy od każdego indywidualnie. Na początek zarekomendowałbym Visual Studio Code lub CLion. Osoby bardziej ambitne, chcące zbudować sobie swoje własne środowisko od podstaw zachęcam do spróbowania Vima lub Emacsa. W internecie znajdziemy setki poradników, jak to zrobić.
Na kolejnych laboratoriach, w szczególności na laboratoriach ocenianych, zakładamy znajomość z wybranym środowiskiem.
Kompilowanie programów #
Kiedy twój edytor stoi już przed tobą otworem, sprawdźmy zatem, czy działa jak należy. Jako pierwsze zadanie stwórz program, wypisujący twoje:
- imię,
- nazwisko,
- nr indeksu.
W przeciwieństwie do poprzedniego semestru tutaj będziemy używać C++. Poniżej znajdziesz najprostszy program wypisujący wybrany tekst na standardowe wyjście.
// Wczytanie definicji funkcji operujących na strumieniach wejścia-wyjścia
// (analogiczne do <stdio.h> z C)
#include <iostream>
int main()
{
// Wypisanie ciągu na standardowe wyjście oraz zakończenie znakiem końca linii
// (analogiczne do puts z C)
std::cout << "Jan Dzban, 123456" << std::endl;
return 0;
}
Powyższy program po rozpoczęciu wypisuje na standardowe wyjście tekst znajdujący się w kodzie i od razu się kończy. Więcej szczegółów obsługi strumieni w C++ dowiesz się na kolejnych warsztatach.
Stwórz plik o nazwie hello.cpp i otwórz go za pomocą twojego edytora.
Skopiuj przykład i zmień jego zawartość na dane opisujące ciebie.
Gdy plik będzie gotowy, uruchom terminal w miejscu utworzenia pliku.
Każde ze środowisk programistycznych powinno mieć opcję uruchomienia terminala w ramach swojego okna.
Skonsultuj dokumentację środowiska, aby odnaleźć tę funkcję.
Będzie bardzo przydatna przez cały semestr.
Jeśli nie uda ci się znaleźć tej funkcji, uruchom terminal w oddzielnym oknie.
Teraz należy skompilować program, aby komputer mógł wykonać przekazane mu instrukcje w języku C++.
Do tego zadania służy kompilator.
Każdy szanujący się system operacyjny dostarczany jest z pewnym kompilatorem języka C.
W dużej mierze w komplecie instalowane są także kompilatory języka C++.
W przypadku naszego laboratorium mamy do dyspozycji kompilatory GCC (GNU Compiler Collection).
Interesować nas będzie program o nazwie g++, który jest kompilatorem języka C++.
Skompiluj swój przykładowy program poleceniem
g++ -o hello hello.cpp
Powyższe polecenie uruchamia kompilator i instruuje go, aby potraktował plik hello.cpp jako kod źródłowy (wejście) oraz wygenerował gotowy program wykonywalny o nazwie hello (wyjście).
Jeśli kod posiada błędy (jest niezgodny ze składnią języka C++), kompilator wypisze błąd i zakończy się niepowodzeniem.
W przeciwnym wypadku w bieżącym katalogu roboczym stworzony zostanie plik hello, który można uruchomić poleceniem
./hello
Dla przykładowego programu wyjście powinno wyglądać
Jan Dzban, 123456
Gdy już mamy możliwość pisania kodu, możemy przejść do dzielenia się nim z innymi programistami.
Git #
Git (z ang. „głupek”) jest programem, tak zwanym systemem kontroli wersji, którego współcześnie używa praktycznie każdy programista. Pozwala on na udostępnianie kodu źródłowego między programistami i modyfikowanie go (zamiast np. wysyłania sobie ręcznie mailem plików z kodem). W połączeniu z serwerem (często github.com) pozwala na przechowywanie kodu w chmurze (czyli na cudzym komputerze). W przypadku naszych laboratoriów Git posłuży nam do współdzielenia kodu między studentami a prowadzącymi. Każde zadanie oceniane będzie udostępniane w tak zwanym repozytorium. Umiejętność korzystania z Gita jest obowiązkowa na wszystkich laboratoriach ocenianych w zakresie pozwalającym na przekazanie rozwiązania zadania laboratoryjnego. Tylko kod znajdujący się w repozytorium na koniec zajęć podlega ocenie!
Poniżej znajduje się prosta instrukcja korzystania z Gita. Osoby zainteresowane zachęcam do głębszego zapoznania z tematem, w szczególności dzięki oficjalnej książce.
1. Konfiguracja Gita #
Przed pierwszym użyciem należy skonfigurować swoją tożsamość:
git config --global user.name "Twoje Imię i Nazwisko"
git config --global user.email "twoj@email.com"
Możesz sprawdzić swoją konfigurację za pomocą:
git config --list
To działanie jest wymagane tylko raz.
2. Podstawowe operacje #
Każdy projekt związany jest z repozytorium – to w nim przechowywany jest kod i jego historia. Utwórz nowe repozytorium i spróbuj wykonać na nim poniższe operacje.
Aby utworzyć repozytorium w aktualnym folderze, należy wykonać
git init
Każdy nowy plik musi zostać dodany do Gita, aby go śledzić:
git add <nazwa pliku>
Do Gita dodajemy tylko kod źródłowy. Nie dodajemy nigdy plików, które powstają przy kompilacji!
Aby sprawdzić, jakie pliki zostały zmodyfikowane od ostatniego zapisania zmian:
git status
Zatwierdzenie zmian zapisuje je w historii repozytorium:
git commit -m "Opis zmian"
Aby sprawdzić historię zapisanych zmian, możemy użyć
git log
3. Repozytoria zdalne – remote #
Repozytoria możemy tworzyć lub klonować z serwera. W przypadku tych zajęć repozytoria będą klonowane przez każdego studenta.
Do tego celu użyjemy systemu sgit.mini.pw.edu.pl. Proszę udać się na tę stronę i zalogować się kontem PW CAS. Od momentu zalogowania na stronie głównej powinny pokazać się repozytoria dostępne dla użytkownika.
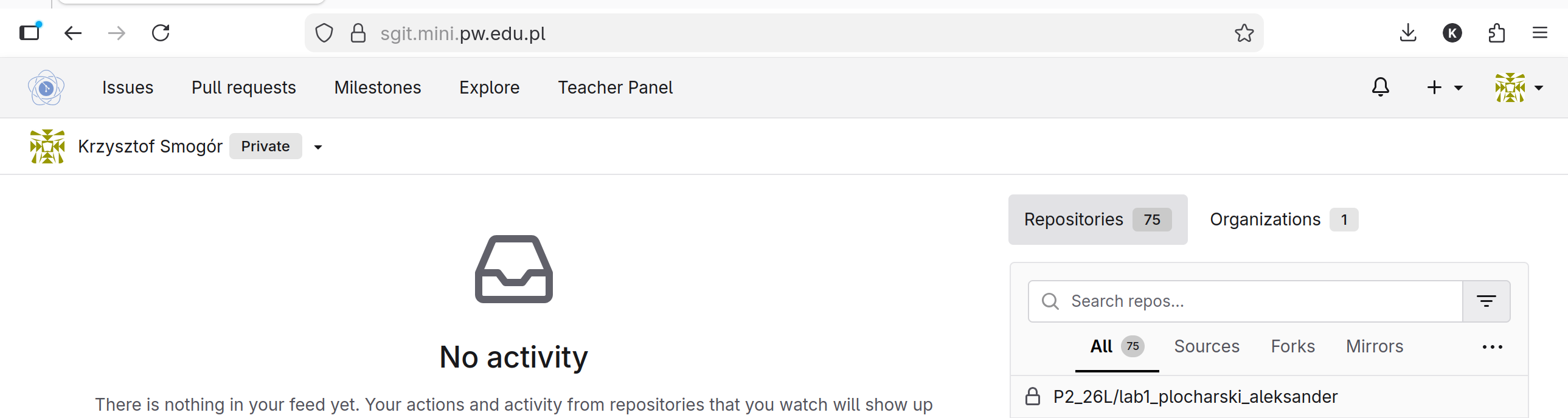
Namierz repozytorium o nazwie lab1_nazwisko_imie i kliknij w nie lewym przyciskiem myszy.
W prawym górnym rogu powinien pojawić się odnośnik do wykonania operacji clone.
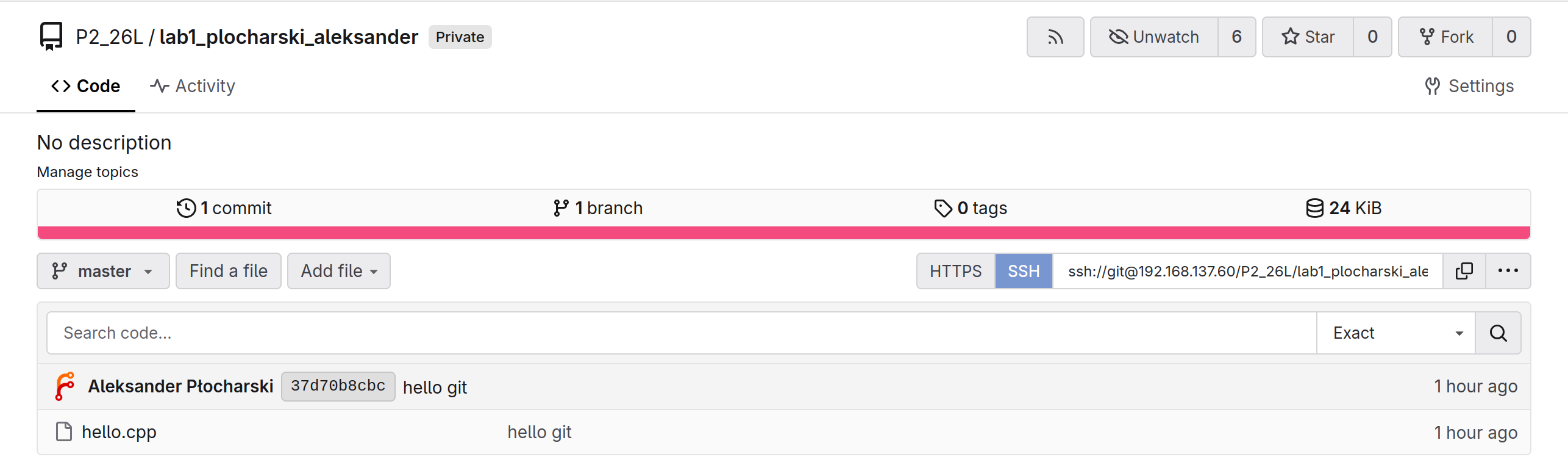
Aby wykonać operacje clone, wydaj następujące polecenie
git clone <adres zdalnego repozytorium>
Polecenie powinno zapytać o hasło i użytkownika. Oznacza to, że nie jesteś autoryzowany do dostępu.
Na czas laboratorium wykorzystamy protokół ssh, aby mieć dostęp do swojego repozytorium.
W tym celu należy przygotować klucz ssh, który pozwoli zidentyfikować, kim jesteśmy i jakie repozytoria możemy pobierać.
Wykonaj następujące polecenia
ssh-keygen -t ed25519 -f ~/.ssh/sgit_id
chmod 600 ~/.ssh/sgit_id
printf "\nHost 192.168.137.60\n HostName 192.168.137.60\n IdentityFile ~/.ssh/sgit_id\n IdentitiesOnly yes\n" >> ~/.ssh/config
cat ~/.ssh/sgit_id.pub
W momencie pytania o hasło do klucza proszę nacisnąć enter bez wpisywania niczego. Powyższe polecenia generują parę kluczy: publiczny i prywatny, ustawiają odpowiednie uprawnienia oraz konfigurują ssh, aby używał nowo utworzonego klucza jako tożsamości. Ostatnia linia jest kluczem publicznym, który musimy umieścić w systemie sgit. W tym celu proszę udać się do ustawień konta w prawym górnym rogu
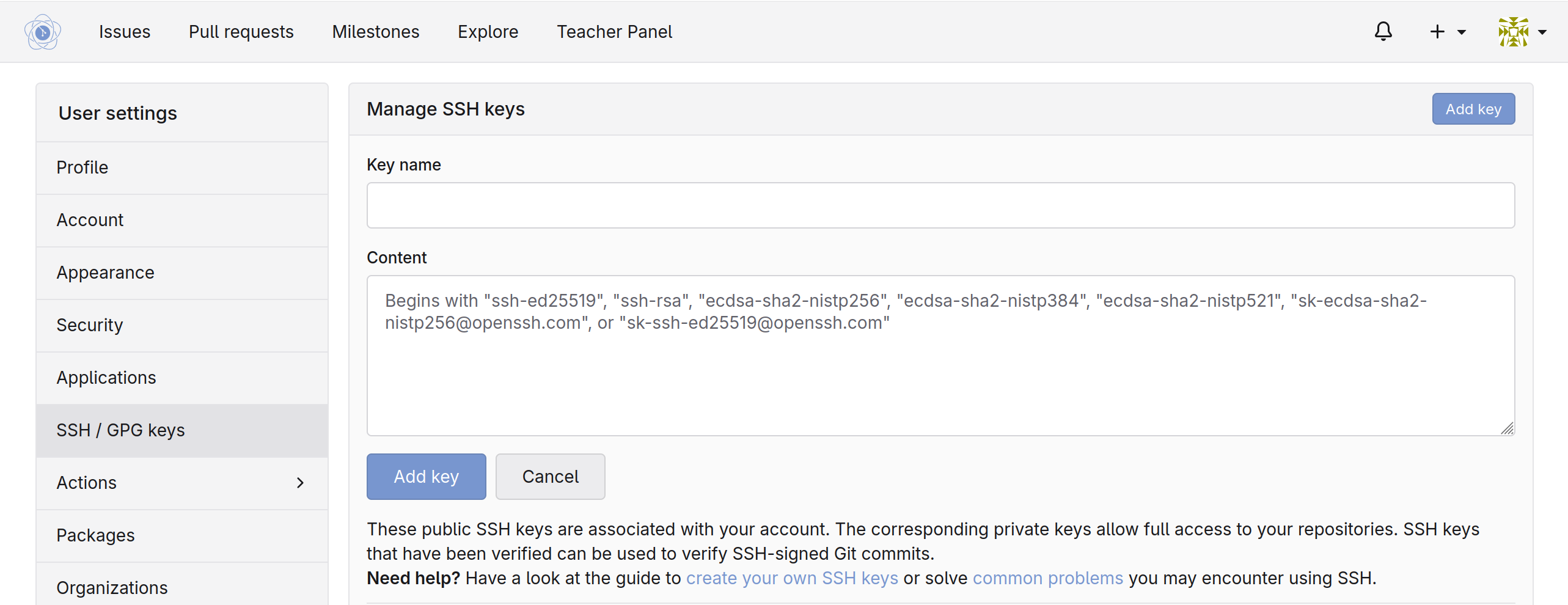
Tam znajdź sekcję SSH / GPG Keys, w której należy dodać nowy klucz i wkleić zawartość klucza publicznego.
Od tego momentu przy próbie wykonania operacji klonowania przy pomocy adresu SSH
git clone ssh://git@192.168.137.60/P2_26L/lab1_nazwisko_imie.git
powinien utworzyć się folder z pustym repozytorium. Można potwierdzić prawidłowo skonfigurowane zdalne repozytorium poprzez wykonanie polecenia
git remote
Powinien być widoczny jeden remote o nazwie origin.
Zadanie na dziś – zaznaczenie obecności #
Aby potwierdzić działanie twojej konfiguracji Gita, twoim zadaniem jest przesłanie przykładowego programu do repozytorium udostępnionego w ramach systemu sgit. Wykonaj następujące kroki:
- Skopiuj plik
hello.cppdo sklonowanego repozytorium (nie kopiuj plikuhello- to każdy może utworzyć z kodu źródłowego). - Dodaj pliki do śledzonych poleceniem
git add hello.cpp. - Potwierdź status repozytorium poprzez
git status. - Zatwierdź zmiany w repozytorium wykonując
git commit -m "Example hello program". - Wyślij zmiany do zdalnego repozytorium poprzez polecenie
git push.
Posłowie – dostęp do repozytoriów sgit spoza wydziału #
Poniższy rozdział jest dodatkowy. Zawiera zaawansowane i potencjalnie praktyczne treści. Zachęcam zainteresowanych do zapoznania się.
Metoda dostępu do repozytorium przedstawiona powyżej działa tylko w obrębie wydziału.
Proszę zwrócić uwagę na adres zdalnego repozytorium 192.168.137.60.
Jest to adres z sieci wewnętrznej.
Nie zadziała z dowolnego miejsca w internecie.
Mamy do wyboru dwie ścieżki, aby rozszerzyć dostęp spoza wydziału:
- połączenie pośrednie SSH do sieci wydziałowej (poprzez
ssh.mini.pw.edu.pl) - konfiguracja dostępu poprzez token i dodanie remote poprzez protokół HTTP
Połączenie pośrednie do sieci wydziałowej #
Skoro do komunikacji z serwerem potrzebujemy znajdować się w sieci wydziałowej, to można wykorzystać metodę ssh port forwarding. Jest to funkcjonalność protokołu ssh, która pozwala przesłać wybrany ruch sieciowy do serwera ssh.
Najpierw należy połączyć się z serwerem ssh.mini.pw.edu.pl i podać parametr -L w taki sposób
ssh -L 22222:192.168.137.60:22 {login_wydzialowy}@ssh.mini.pw.edu.pl
To polecenie mówi, aby w ramach sesji ssh otworzył się tunel, który zmapuje port 22222 na maszynie klienckiej na połączenie z 192.168.137.60:22 po stronie serwera.
W momencie, gdy mamy otwartą sesję ssh, w drugim terminalu proszę wykonać następujące polecenie w już sklonowanym repozytorium
git remote add foreign_origin ssh://git@localhost:22222/P2_26L/lab1_nazwisko_imie.git
Powyższe rozwiązanie wymaga utrzymywania dodatkowego remote poza wydziałem.
Wymaga to także świadomego wykonywania operacji push i pull w zależności od aktualnie użytkowanej sieci.
Token dostępowy – protokół HTTP #
Alternatywą jest utworzenie tokenu dostępowego w interfejsie sgit i skonfigurowanie credential helpera w ramach gita.
Najpierw należy utworzyć token dostępowy w ustawieniach konta.
Upewnij się, że token ma uprawnienia do prywatnych repozytoriów na poziomie read/write.
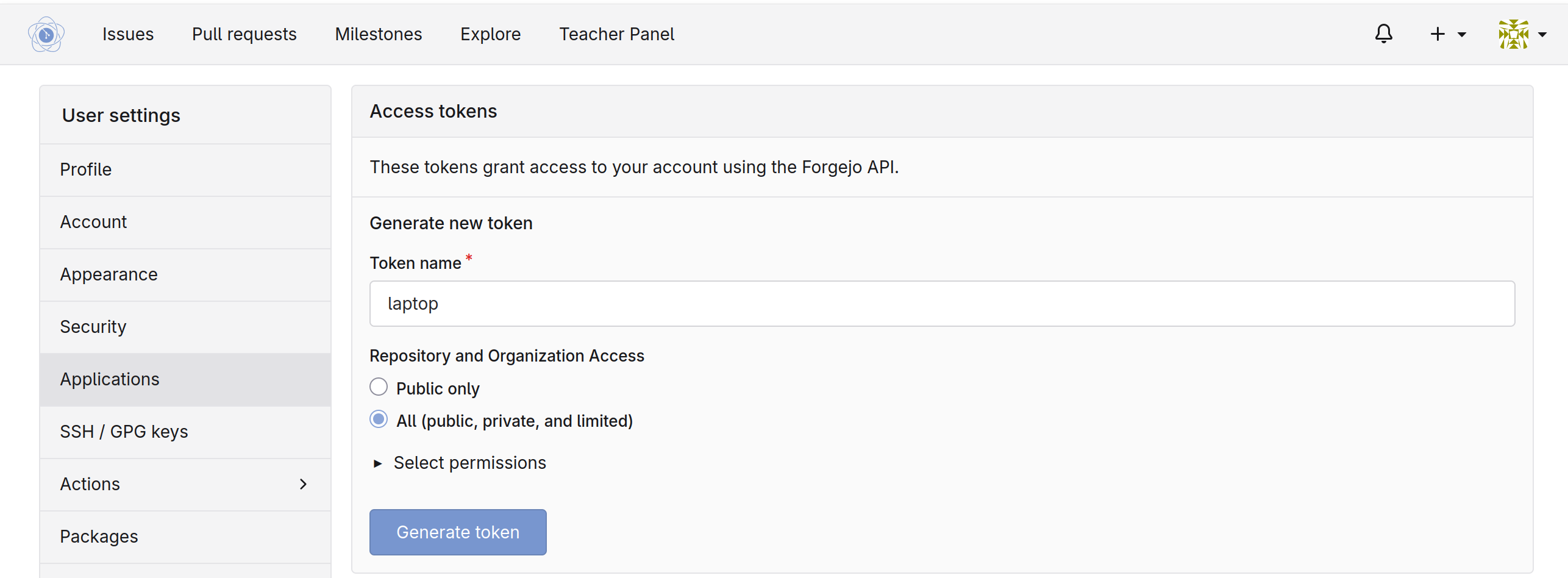
Po wygenerowaniu tokenu zapisz go sobie na boku. Teraz wykonaj następujące polecenie
git config --global credential.helper 'store --file ~/.git-credentials'
chmod 600 ~/.git-credentials
To spowoduje, że git przy każdym podaniu loginu i hasła zapamięta je w pliku tekstowym. Niektóre konfiguracje Linuxa wspierają menadżery sekretów. Polecam dowiedzieć się jaki menadżer dostępny jest w twoim systemie i zintegrowanie się z nim zgodnie z tą instrukcją.
Teraz wykonajmy operacje clone repozytorium po protokole HTTP
git clone https://sgit.mini.pw.edu.pl/P2_26L/lab1_nazwisko_imie.git
Git zapyta nas o login i hasło. Tym razem należy mu je podać. Login można odnaleźć w górnym rogu przy profilu użytkownika
Hasło to token wygenerowany w pierwszym kroku.
Przy prawidłowej konfiguracji operacja clone powinna się powieść.
Kolejne połączenia z serwerem powinny skorzystać z zapisanego tokenu w pliku ~/.git-credentials