Wykład 4 - Narzędzia #
Zakres:
- Git
- Budowanie:
- build types
- cmake
- Debugging:
- gdb
- coredumps
- sanitizers
- Testowanie
- Zarządzanie zależnościami
Git #
Git jest rozproszonym systemem kontroli wersji. Dostarcza narzędzia do zarządzania repozytorium. Repozytorium to nic innego jak zbiór utrwalonych stanów katalogu roboczego. Taki utrwalony stan to commit.
Repozytorium zwykle ma postać folderu .git przechowywanego wewnątrz katalogu roboczego.
W środku znajdują się pliki opisujące commity, w tym zapisana treść katalogu roboczego.
mkdir repo
cd repo
git init
ls -l .git
Takie polecenie utworzy w pustym katalogu roboczym puste repozytorium: niezawierające jeszcze żadnych zapisanych wersji.
-rw-rw-r-- 1 user user 92 mar 22 10:11 config # Lokalna konfiguracja repozytorium
-rw-rw-r-- 1 user user 73 mar 22 10:11 description # Czytelny opis repozytorium
-rw-rw-r-- 1 user user 23 mar 22 10:11 HEAD # Wskazanie na "bieżący" commit
drwxrwxr-x 4 user user 4096 mar 22 10:11 objects # Przechowywane obiekty: commity, stany plików, stany katalogów
drwxrwxr-x 4 user user 4096 mar 22 10:11 refs # Referencje, czyli nazwy dla commitów
Katalog roboczy razem z .git można dowolnie przenosić i kopiować, .git nie zawiera żadnych absolutnych ścieżek.
Usunięcie katalogu .git usuwa repozytorium wraz ze wszystkimi informacjami kontroli wersji, ale oczywiście
nie dotyka samego katalogu roboczego.
Obiekty #
Repozytorium składa się z obiektów, przechowywanych w katalogu .git/objects.
Git definiuje 4 rodzaje obiektów (blob, tree, commit, annotated tag), z czego najistotniejsze są pierwsze 3:
- blob: utrwalona zawartość jakiegoś pliku z katalogu roboczego
- tree: utrwalona zawartość katalogu (słownika)
- commit: utrwalony stan katalogu roboczego z dodatkowymi informacjami nt. wersji
Obiekty po utworzeniu są niemodyfikowalne, nie można zmieniać ich zawartości. Dzięki temu zawartość obiektów może posłużyć do ich identyfikacji! Git rozpoznaje obiekty na podstawie skrótu SHA-1 ich zawartości. Skrót zależy tylko i wyłącznie od zawartości. Zmiana zawartości = zmiana identyfikatora = inny obiekt.
Można ręcznie wyliczyć skrót pliku poleceniem hash-object. Nie trzeba do tego posiadać nawet repozytorium:
echo Hi! > hi.txt
git hash-object hi.txt # 663adb09143767984f7be83a91effa47e128c735
Wyliczony skrót będzie taki sam na każdej maszynie, bo zawartość pliku jest taka sama. Zmieniając treść, zmienimy skrót.
Plik dodany do repozytorium, np. jako element commit’a zostanie umieszczony w katalogu objects jako obiekt typu blob i będzie identyfikowany jego skrótem.
cd repo
echo Hi! > hi.txt
git add hi.txt
git commit -m "Initial commit"
cat .git/objects/66/3adb09143767984f7be83a91effa47e128c735 | zlib-flate -uncompress | xxd
git cat-file blob 663ad
Katalog .git/objects jest partycjonowany po dwóch pierwszych znakach skrótu.
Jak widać na powyższym przykładzie, do identyfikacji obiektów
wystarczy podać kilka pierwszych znaków sumy SHA1. Wystarczy tyle,
żeby nie było niejednoznaczności.
Utrwalenie stanu pliku nie jest wystarczające do wersjonowania projektu: trzeba zapisywać stany całych katalogów. Do tego służy obiekt typu tree.
Za pomocą polecenia git commit utworzyliśmy kilka obiektów:
cd repo
find .git/objects -type f
git cat-file -t 8da9
git ls-tree 8da9
Jeden z nich to właśnie tree. Jego zawartość to listing katalogu, którego stan opisuje.
100644 blob 663adb09143767984f7be83a91effa47e128c735 hi.txt
Nasz obiekt zawiera tylko jeden wpis, bo katalog roboczy miał tylko 1 plik w momencie wywołania polecenia git commit.
Obiekt tree listuje elementy katalogu, każdy z nich jest innym obiektem git’a. Dla każdego obiektu zawiera:
- uprawnienia (100644 = rw-r–r–)
- typ (blob/tree)
- identyfikator obiektu (SHA1)
- nazwę obiektu w katalogu (hi.txt)
Tree może zawierać inne obiekty tree. Pozwala opisywać dowolnie zagnieżdżone struktury katalogów.
graph TD
X[Commit\nda14b73] --> B
B[Tree\n8dab03]
B --> C[Blob\nfe493f7]
B --> D[Blob\n28c7351]
B --> E[Tree\n9c75956]
E --> F[Blob\nab2ea75]
E --> G[Blob\ndb09143]Jeżeli katalog zawiera kilka plików o tej samej zawartości, to tree będzie wielokrotnie listował ten sam obiekt.
cd repos
cp hi.txt hey.txt
git add hey.txt
git commit -m "Copied hi.txt"
git ls-tree a5250
100644 blob 663adb09143767984f7be83a91effa47e128c735 hey.txt
100644 blob 663adb09143767984f7be83a91effa47e128c735 hi.txt
Identyfikator obiektu tree to skrót SHA1 tej listy, zawierającej skróty zawieranych elementów. Zmiana zawartości hi.txt skutkuje zmianą jego skrótu, to z kolei spowoduje zmianę zawartości tree katalogu głównego i w konsekwencji zmianę jego skrótu.
Commity to główne obiekty repozytorium tworzone w momencie utrwalania wersji projektu.
git cat-file commit a7f3
tree a5250f7c6ad5260e28003ba5a0b1841b752918e3
parent 23d9585ca2a2fe493f79c75956ab4d815da14b73
author Paweł Sobótka <pawel.sobotka@pw.edu.pl> 1742665566 +0100
committer Paweł Sobótka <pawel.sobotka@pw.edu.pl> 1742665566 +0100
Copied hi.txt
Można z niego odczytać:
- identyfikator utrwalonego stan katalogu roboczego (
tree) - identyfikatory poprzednich commitów (
parent) - autor (
author) - czas autorstwa (utrwalenia stanu) (
1742665566 +0100) - committer (
commiter) - czas commiterstwa (nałożenia commita) (
1742665566 +0100) - wiadomość opisująca wersję (
Copied hi.txt)
Commit zawiera stan całego projektu, a nie wprowadzone zmiany!
Podobnie jak wcześniej, SHA1 commit’a to skrót liczony za powyższe pola. Zmiana któregokolwiek wymusza powstanie nowego commita o innym SHA1.
Branche #
Posługiwanie się sumami SHA1 nie należy do najprzyjemniejszych dla człowieka.
Zamiast mówić: popatrz sobie na wersję 23d9585ca2a2fe493f79c75956ab4d815da14b73 łatwiej
byłoby mieć mnemoniczną nazwę dla rewizji. Takie referencje to znane powszechnie branche.
Branche można wylistować:
git branch -v
# * master a7f3d48 Copied hi.txt
Technicznie branche to pliki w folderze .git/refs/heads/ przechowujące SHA1 commita, który nazywają:
cat .git/refs/heads/master
# a7f3d48e135b4f4deb9a985ed7058b70491d7c71
Listowanie branchy to tak naprawdę listowanie tego katalogu. Tworzenie brancha wskazującego na jakiś commit po prostu tworzy podobny plik.
git branch feature a7f3d48
git branch -v
# feature a7f3d48 Copied hi.txt
# * master a7f3d48 Copied hi.txt
ls -l .git/refs/heads
# feature master
Stąd ważny fakt:
Branch to nic więcej jak nazwa dla commita!
Branche mogą być modyfikowalne. W momencie tworzenia nowego commita aktywny branch jest przepinany na nowy commit. Git wspiera również niemodyfikowalne nazwy dla commitów, czyli tzw. tagi.
HEAD #
A co to jest aktywny branch? Repozytorium zawiera specjalną referencję o nazwie HEAD
(w pliku .git/HEAD), która pokazuje aktualny commit, na którym pracujemy.
HEAD może pokazywać na commit pośrednio poprzez branch lub bezpośrednio.
Typową sytuacją jest wskazanie pośrednie:
cat .git/HEAD
# ref: refs/heads/master
To sytuacja, w której kolokwialnie mówimy, że jesteśmy na branchu. HEAD wskazuje
na master, który wskazuje na konkretny commit. Zarówno HEAD jak i master są nazwami tego samego
commita.
graph LR
%% Definitions by type
classDef commitStyle fill: #f9a825, stroke: #333, stroke-width: 2px, font-weight: bold;
classDef treeStyle fill: #8bc34a, stroke: #333, stroke-width: 2px, font-weight: bold;
classDef blobStyle fill: #03a9f4, stroke: #333, stroke-width: 2px, font-weight: normal;
classDef ref fill: #add8e6, stroke: none, color: #000, font-family: monospace, font-size: 12px, padding: 2px, rx: 5px, ry: 5px;
%% Commit Nodes (Left-Aligned)
HEAD:::ref
master:::ref
C0[NULL]:::textOnly
C1[Commit 23d9]:::commitStyle
C2[Commit a7f3]:::commitStyle
C2 -->|parent| C1
C1 -->|parent| C0
C1 -->|tree| T1
C2 -->|tree| T2
HEAD --> master
master --> C2
Hi[Blob 663a]:::blobStyle
T1[Tree 8da9]:::treeStyle
T2[Tree a525]:::treeStyle
T1 --> Hi
T2 --> Hi
T2 --> HiDo manipulacji HEAD‘em służy operacja git checkout, która oczekuje jako argumentu jakiegoś
commita. Zmiana HEAD’a zmienia stan katalogu roboczego na ten zapisany w docelowym commicie.
git checkout 23d9
cat .git/HEAD
# 23d9585ca2a2fe493f79c75956ab4d815da14b73
HEAD wskazuje teraz bezpośrednio na commit. To tzw. detached HEAD state: normalny w przypadku przeglądania
starych rewizji.
graph LR
%% Definitions by type
classDef commitStyle fill: #f9a825, stroke: #333, stroke-width: 2px, font-weight: bold;
classDef treeStyle fill: #8bc34a, stroke: #333, stroke-width: 2px, font-weight: bold;
classDef blobStyle fill: #03a9f4, stroke: #333, stroke-width: 2px, font-weight: normal;
classDef ref fill: #add8e6, stroke: none, color: #000, font-family: monospace, font-size: 12px, padding: 2px, rx: 5px, ry: 5px;
%% Commit Nodes (Left-Aligned)
HEAD:::ref
master:::ref
C0[NULL]:::textOnly
C1[Commit 23d9]:::commitStyle
C2[Commit a7f3]:::commitStyle
C2 -->|parent| C1
C1 -->|parent| C0
HEAD --> C1
master --> C2Commit wskazywany przez HEAD staje się automatycznie rodzicem nowo tworzonych rewizji.
git checkout master # HEAD -> master -> a7f3
touch empty.txt
git add empty.txt
git commit -m "Add empty file"
# [master eef04fe] Add empty file
# 1 file changed, 0 insertions(+), 0 deletions(-)
# create mode 100644 empty.txt
git cat-file commit eef0
# tree 580e44691fcd53fb04aebbd71fe23b5c626afec8
# parent a7f3d48e135b4f4deb9a985ed7058b70491d7c71
# author Paweł Sobótka <pawel.sobotka@pw.edu.pl> 1742673019 +0100
# committer Paweł Sobótka <pawel.sobotka@pw.edu.pl> 1742673019 +0100
#
# Add empty file
Dodatkowo podczas takiej operacji aktywny branch jest przesuwany na nowy commit. W przypadku detached HEAD nie ma aktywnego brancha, więc nie jest to naturalny stan do tworzenia nowych commitów.
Index #
Przed wyprodukowaniem commita zwykle wydajemy polecenie git add - po co?
Istnieją 3 niezależne stany katalogu roboczego, które biorą udział w procesie tworzenia commita:
- Sam katalog roboczy z bieżącym stanem plików
HEAD- względem niego wypracowywujemy zmianę (będzie rodzicem)- Indeks - stan pośredni, do którego selektywnie dodajemy zmiany przed utworzeniem commita
Pozwala to na selektywne wypracowywanie treści następnego commita. Możemy, np. mieć jakieś prywatne, brudne zmiany w części plików, których nie chcemy uwzględniać w nowej rewizji. Nie chcemy ich też wycofywać, bo są przydatne.
Indeks technicznie znajduje się wpliku .git/index. Można go wydrukować poleceniem ls-files:
git ls-files --stage
# 100644 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 0 empty.txt
# 100644 663adb09143767984f7be83a91effa47e128c735 0 hey.txt
# 100644 663adb09143767984f7be83a91effa47e128c735 0 hi.txt
Wygląda zaskakująco podobnie do obiektu tree bo właśnie nim (prawie) jest!
W momencie operacji git commit to właśnie stan indeksu utrwalany jest w postaci
nowego obiektu tree, wokół którego powstaje nowy obiekt commit.
Operacja git checkout przywraca nie tylko stan katalogu roboczego, na taki jak jest zapisany
w checkoutowanym commicie, ale też zrównuje z nim stan indeksu.
W czystym stanie repozytorium mamy HEAD == index == workdir.
git status
# Na gałęzi master
# nic do złożenia, drzewo robocze czyste
Wprowadzając zmiany w katalogu roboczym otrzymujemy: HEAD == index != workdir.
echo "not really" > empty.txt
git status
# Na gałęzi master
# Zmiany nie przygotowane do złożenia:
# (użyj „git add <plik>...”, żeby zmienić, co zostanie złożone)
# (użyj „git restore <plik>...”, aby odrzucić zmiany w katalogu roboczym)
# zmieniono: empty.txt
#
# brak zmian dodanych do zapisu (użyj „git add” i/lub „git commit -a”)
git diff
# git diff
# diff --git a/empty.txt b/empty.txt
# index e69de29..4d0c7d7 100644
# --- a/empty.txt
# +++ b/empty.txt
# @@ -0,0 +1 @@
# +not really
Polecenie git diff porównuje stan katalogu roboczego ze stanem indeksu.
Dodając zmianę do indeksu otrzymujemy HEAD != index == workdir:
git add empty.txt
git status
# Na gałęzi master
# Zmiany do złożenia:
# (użyj „git restore --staged <plik>...”, aby wycofać)
# zmieniono: empty.txt
git diff
#
git diff --cached
# diff --git a/empty.txt b/empty.txt
# index e69de29..4d0c7d7 100644
# --- a/empty.txt
# +++ b/empty.txt
# @@ -0,0 +1 @@
# +not really
git diff --cached pokazuje indeks ze stanem HEAD.
W momencie dodania do indeksu powstają nowe obiekty blob i tree, które będą później
utrwalane w nowym commicie.
Można teraz ponownie zmienić stan katalogu roboczego uzyskując HEAD != index != workdir:
echo "hey!" > empty.txt
# git status
# Na gałęzi master
# Zmiany do złożenia:
# (użyj „git restore --staged <plik>...”, aby wycofać)
# zmieniono: empty.txt
#
# Zmiany nie przygotowane do złożenia:
# (użyj „git add <plik>...”, żeby zmienić, co zostanie złożone)
# (użyj „git restore <plik>...”, aby odrzucić zmiany w katalogu roboczym)
# zmieniono: empty.txt
#
git diff
# diff --git a/empty.txt b/empty.txt
# index 4d0c7d7..d4c3701 100644
# --- a/empty.txt
# +++ b/empty.txt
# @@ -1 +1 @@
# -not really
# +hey!
Wykonując teraz polecenie git commit:
- indeks zostanie utrwalony w postaci nowego obiektu
tree - powstanie nowy obiekt
commit:- wskazujący na nowo powstałe
tree - obecny
HEADwstawiony zostanie do atrybutuparent
- wskazujący na nowo powstałe
- gałąź wskazywana przez
HEADzostanie przestawiona na nowy commit
Otrzymamy w ten sposób HEAD = index != workdir. W katalogu roboczym pozostanie
ostatnio wprowadzona zmiana. git commit nie dotyka katalogu roboczego.
git commit -m "Filled empty file"
# [master 401c27f] Filled empty file
# 1 file changed, 1 insertion(+)
git status
# Na gałęzi master
# Zmiany nie przygotowane do złożenia:
# (użyj „git add <plik>...”, żeby zmienić, co zostanie złożone)
# (użyj „git restore <plik>...”, aby odrzucić zmiany w katalogu roboczym)
# zmieniono: empty.txt
#
# brak zmian dodanych do zapisu (użyj „git add” i/lub „git commit -a”)
Reset #
Jedna z podstawowych operacji: git reset, często powoduje trudności ze względu
na swoją wielofunkcyjność. Wbrew destrukcyjnie brzmiącej nazwie reset w istocie
przestawia branch na wskazany commit. Dodatkowo potrafi w tym samym momencie zmieniać stan indeksu
i katalogu roboczego na stan z danej rewizji.
git reset ma 3 tryby:
git reset --soft przestawia referencję zapisaną w HEAD na wskazany commit.
Nie zmienia przy tym stanu katalogu roboczego ani indeksu.
git reset --soft HEAD^
# git status
# Na gałęzi master
# Zmiany do złożenia:
# (użyj „git restore --staged <plik>...”, aby wycofać)
# zmieniono: empty.txt
#
# Zmiany nie przygotowane do złożenia:
# (użyj „git add <plik>...”, żeby zmienić, co zostanie złożone)
# (użyj „git restore <plik>...”, aby odrzucić zmiany w katalogu roboczym)
# zmieniono: empty.txt
Wróciliśmy tym samym do stanu HEAD != index != workdir, niejako odwracając operację git commit.
Commit, mimo że nienazwany ciągle istnieje, możemy do niego wrócić:
git reset --soft 401c
git reset --mixed robi to co --soft i dodatkowo przywraca stan indeksu na wskazany commit:
git reset --mixed HEAD^
git diff
# diff --git a/empty.txt b/empty.txt
# index e69de29..d4c3701 100644
# --- a/empty.txt
# +++ b/empty.txt
# @@ -0,0 +1 @@
# +hey!
Mamy teraz HEAD = index != workdir. Katalog roboczy został niedotknięty.
git reset --hard zmienia wszystko: HEAD branch, stan indeksu i stan katalogu roboczego
na stan ze wskazanej rewizji. Nieodwracalnie porzuca zmiany w katalogu roboczym!
git reset --hard 401c
git status
# Na gałęzi master
# nic do złożenia, drzewo robocze czyste
Merge #
Repozytorium to zbiór commitów. Każdy commit zawiera listę odniesień do swoich przodków (0-n). Każde repozytorium jest zatem acyklicznym grafem skierowanym, w którym węzłami są commity, a krawędziami wskazania na przodków.
Graf można zwizualizować poleceniem git log:
git log --oneline --graph --all
# * 401c27f (HEAD -> master) Filled empty file
# * eef04fe Add empty file
# * a7f3d48 (feature) Copied hi.txt
# * 23d9585 Initial commit
Na tą chwilę nasz graf jest listą. Projekt rozwijał się liniowo.
Jeden commit może być przodkiem kilku różnych rewizji. Dzieje się tak zwykle, gdy kilku autorów w podobnym czasie zaczyna rozwijać projekt, wychodząc z tej samej rewizji.
git checkout feature
echo "Feature Hi!" > hi.txt
git add hi.txt
git commit -m "Featurized hi.txt"
git log --oneline --graph --all
# * 5e11eea (HEAD -> feature) Featurized hi.txt
# | * 401c27f (master) Filled empty file
# | * eef04fe Add empty file
# |/
# * a7f3d48 Copied hi.txt
# * 23d9585 Initial commit
Na commicie a7f3d48 nastąpiło rozwidlenie historii projektu. Zwykle, w pewnym momencie
niezależnie rozwijane gałęzie muszą ulec połączeniu celem wypracowania jednej, spójnej rewizji
integrującej całą równoległą pracę. Służy do tego operacja git merge tworząca commity
o wielu przodkach.
git merge --no-edit master
git log --oneline --graph --all
# * 1296142 (HEAD -> feature) Merge branch 'master' into feature
# |\
# | * 401c27f (master) Filled empty file
# | * eef04fe Add empty file
# * | 5e11eea Featurized hi.txt
# |/
# * a7f3d48 Copied hi.txt
# * 23d9585 Initial commit
git cat-file -p HEAD
# tree 8c1f710ff54a3848913a130fbd58b1247827b1ed
# parent 5e11eea4a4f3199d1a097e0716c4afa1c0724317
# parent 401c27fd94595bc9565d76e389fa5923febf2302
# author Paweł Sobótka <p.sobotka@oxla.com> 1742684714 +0100
# committer Paweł Sobótka <p.sobotka@oxla.com> 1742684714 +0100
#
# Merge branch 'master' into feature
Nowo utworzony merge-commit scala stan katalogu roboczego zapisany w jego dwóch przodkach.
Jednym przodkiem zawsze jest HEAD, drugim to co wskazaliśmy w argumencie.
Integracja przebiegła automatycznie, bo zmiany nie były konfliktujące.
Do scalania zmian git stosuje algorym znany jako three way merge. Bierze on pod uwagę
trzy stany katalogu roboczego: dwa ze scalanych commitów (HEAD -> development -> 5e11eea i master -> 401c27f)
oraz ich najbliższego wspólnego przodka: punkt rozwidlenia a7f3d48.
graph LR
classDef commit fill: #f9a825, stroke: #333, stroke-width: 2px, font-weight: bold, rx: 2px, ry: 2px
classDef new fill: #90EE90, stroke: #333, stroke-width: 2px, font-weight: bold, rx: 2px, ry: 2px
classDef ref fill: #add8e6, stroke: none, color: #000, font-family: monospace, font-size: 12px, padding: 2px, rx: 5px, ry: 5px;
development:::ref --> A
%% development:::ref -.-> M
A["5e11eea\n'Feature Hi!'"]:::commit
B["401c27f\n'Hi!'"]:::commit
C["a7f3d48\n'Hi!'"]:::commit
M["1296142\n'Feature Hi!'"]:::new
A --> C
B --> C
M --> A
M --> B
master:::ref --> BW powyższym przypadku zawartość blob’a jest taka sama w jednej ze scalanych wersji jak w ich wspólnym przodku. To czyni operację merge trywialną: wybierana jest wersja, która się odróżnia. Algorytm zakłada, że jeżeli stan w jednej z gałęzi się nie zmienił a w drugiej tak, to ta druga jest pożądaną zmianą po scaleniu.
Jeżeli wszystkie 3 wersje są takie same, sprawa jest jasna. Co jednak w przypadku, kiedy wszystkie są różne? W takim przypadku mamy do czynienia z konfliktem zmian.
git reset --hard HEAD^
git checkout master
echo "Master Hi!" > hi.txt
git add hi.txt && git commit -m "Masterized hi.txt"
git merge feature
# Auto-scalanie hi.txt
# KONFLIKT (zawartość): Konflikt scalania w hi.txt
# Automatyczne scalanie nie powiodło się; napraw konflikty i złóż wynik.
graph LR
classDef commit fill: #f9a825, stroke: #333, stroke-width: 2px, font-weight: bold, rx: 2px, ry: 2px
classDef new fill: #90EE90, stroke: #333, stroke-width: 2px, font-weight: bold, rx: 2px, ry: 2px
classDef ref fill: #add8e6, stroke: none, color: #000, font-family: monospace, font-size: 12px, padding: 2px, rx: 5px, ry: 5px;
development:::ref --> A
%% development:::ref -.-> M
A["5e11eea\n'Feature Hi!'"]:::commit
B["401c27f\n'Master Hi!'"]:::commit
C["a7f3d48\n'Hi!'"]:::commit
M["1296142\n???"]:::new
A --> C
B --> C
M --> A
M --> B
master:::ref --> BOperacja git merge jest wykonana częściowo i została zatrzymana przed
wypracowaniem scalonego commita. Katalog roboczy i indeks zawierają teraz częściowo scalony stan.
Pliki, których algorym nie mógł przetworzyć automatycznie,
zawierają znaczniki w miejscach, w których wykryto konflikty.
cat hi.txt
# <<<<<<< HEAD
# Master Hi!
# =======
# Feature Hi!
# >>>>>>> feature
Odpowiedzialnością użytkownika jest teraz ręczne rozwiązanie konfliktów, pozostawiając zamiast tych oznaczonych miejsc poprawną treść.
echo "Feature master Hi!" > hi.txt
git add hi.txt
git commit
Merge to tylko jedno z narzędzi do łączenia zmian, które posiada git.
Zachęcamy do zapoznania się z innymi: rebase, rebase -i, cherry-pick.
Remote #
Git jest rozproszonym systemem kontroli wersji służącym do pracy nad tym samym projektem na wielu stacjach roboczych. Typowo, każdy autor posiada na swojej maszynie własne repozytorium i synchronizuje jego zawartość z repozytoriami zdalnymi, korzystając z danego protokołu sieciowego do wymiany obiektów (np. http lub ssh). Identyfikatory obiektów (SHA1) wyliczane z ich zawartości są identyfikatorami globalnymi, będą zgodne we wszystkich repozytoriach.
Adresy zdalnych repozytoriów muszą być skonfigurowane w lokalnym repozytorium w pliku .git/config
za pomocą polecenia git remote. Na potrzeby nauki można wskazać jako remote inny katalog
na tej samej maszynie.
mkdir origin && cd origin
git init -b null
cd repo
git remote add origin ../origin
Klonując repozytorium git automatycznie dodaje remote
o nazwie origin wskazujący na miejscie z którego klonujemy.
Istnieją jedynie 4 polecenia komunikujące się ze zdalnym repozytorium:
git clonegit fetchgit pullgit push
Wszystko inne nie dotyka w żaden sposób zdalnej kopii.
git push aktualizuje zdalne referencje.
Powoduje, że branch w zdalnym repozytorium odpowiadający lokalnemu branchowi
pokazuje na ten sam commit co lokalnie. W konsekwencji przesyła obiekty: commit, tree, blob
które mogą nie być obecne w repozytorium zdalnym.
git push --set-upstream origin master
# Wymienianie obiektów: 11, gotowe.
# Zliczanie obiektów: 100% (11/11), gotowe.
# Kompresja delt z użyciem do 8 wątków
# Kompresowanie obiektów: 100% (7/7), gotowe.
# Zapisywanie obiektów: 100% (11/11), 976 bajtów | 976.00 KiB/s, gotowe.
# Razem 11 (delty 0), użyte ponownie 0 (delty 0), paczki użyte ponownie 0
# To ../origin
# * [new branch] master -> master
# branch 'master' set up to track 'origin/master'.
Domyślnie git nie wie jaka zdalna gałąź odpowiada lokalnej gałęzi master.
Konfigurujemy to jednorazowo za pomocą --set-upstream.
Zdalne repozytorium było puste - nie zawierało żadnych obiektów.
git push utworzył zdalną gałąź master, a następnie ustawił ją na commit 401c.
Musiał do tego przesłać ten commit i wszystkie jego zależności, przechodząc
przez wskazania parent aż do początku repozytorium.
git branch -va
# feature a7f3d48 Copied hi.txt
# * master 401c27f Filled empty file
# remotes/origin/master 401c27f Filled empty file
Operacje na zdalnych repozytoriach nie tylko manipulują referencjami w zdalnym repozytorium
ale i lokalnymi ich odpowiednikami. git push utworzył w lokalnym repozytorium referencję origin/master
która pokazuje na to samo co master w repozytorium origin. Takie referencje to nie branche,
nie można ich przestawiać inaczej, niż komunikując się ze zdalnym repozytorium.
W repozytorium mogą asynchronicznie pojawić się zmiany: nowe commity, nowe branche:
cd origin
git checkout -b development master
echo "int main() { return 0; }" > main.cpp
git add main.cpp && git commit -m "Added main.cpp"
git fetch aktualizuje stan wszystkich lokalnych odpowiedników zdalnych branchy,
pobierając przy tym niezbędne obiekty.
git fetch
# remote: Wymienianie obiektów: 4, gotowe.
# remote: Zliczanie obiektów: 100% (4/4), gotowe.
# remote: Kompresowanie obiektów: 100% (2/2), gotowe.
# remote: Razem 3 (delty 1), użyte ponownie 0 (delty 0), paczki użyte ponownie 0
# Rozpakowywanie obiektów: 100% (3/3), 287 bajtów | 287.00 KiB/s, gotowe.
# Z ../origin
# * [nowa gałąź] development -> origin/development
git branch -va
# feature a7f3d48 Copied hi.txt
# * master 401c27f Filled empty file
# remotes/origin/development e0e64f5 Added main.cpp
# remotes/origin/master 401c27f Filled empty file
W lokalnym repo pojawiła się nowa referencja origin/development wskazująca na ten sam, nowy commit co w repo zdalnym.
Możemy teraz utworzyć tam gałąź i rozwijać dalej z teog miejsca:
git checkout development
git pull to złożenie dwóch operacji: git fetch + git merge [remote ref].
Czyli robi dokładnie to co fetch i następnie łączy lokalną gałąź z jej zdalnym odpowiednikiem
potencjalnie tworząc merge commit.
Rodzaje kompilacji #
Ten sam projekt może zostać zbudowany na wiele różnych sposobów, w zależności od późniejszego wykorzystania binariów. Istnieje mnóstwo przełączników kompilatora, sterujących procesem translacji, wypływających na to, co zostanie wygenerowane w zawartości pliku wynikowego.
Flaga -g zapisuje w pliku wynikowym informacje dla debugera.
Flagi z rodziny -W: -Wall, -Wextra, -Wpedantic, -Wshadow, -Wno-shadow
włączają i wyłączają różnorodne ostrzeżenia kompilatora.
Flagi z rodziny -O: -O0, -O1, -O2, -O3, -Os, -Ofast, -Og, -Oz
sterują poziomem optymalizacji. Kolejne poziomy 0, 1, 2, 3
dodają coraz więcej przyśpieszeń, wydłużając proces kompilacji
i przyśpieszając generowany kod.
Flagi z rodziny -fsanitize= załączają różnorodne opcje instrumentacji
programu, ułatwiając wczesne wykrywanie błędów, spowalniając jego wykonanie.
Programiści zwykle wprowadzają kilka różnych typów kompilacji
różniących się zestawami flag. Minimalnie wyróżnia się
typ Debug i Release. Pierwszy jest używany przez programistów
podczas rozwoju oprogramowania. Drugi używany jest do budowy oprogramowania dostarczanego odbiorcom.
Przykładowe zestawy flag:
Debug:-g -Wall -O0 -fsanitize=address,undefinedRelease:-O3 -DNDEBUG
g++ -g -Wall -O0 -fsanitize=address,undefined sum.cpp -o sum.debug
g++ -O3 -DNDEBUG -o sum.release sum.cpp -o sum.release
ll -h
# -rw-rw-r-- 1 user user 700 kwi 6 16:41 sum.cpp
# -rwxrwxr-x 1 user user 168K kwi 6 16:42 sum.debug*
# -rwxrwxr-x 1 user user 17K kwi 6 16:42 sum.release*
time ./sum.debug
# debug: 887459712 (6060576us)
#
# real 0m6,082s
# user 0m5,880s
# sys 0m0,204s
time ./sum.release
# release: 887459712 (261209us)
#
# real 0m0,277s
# user 0m0,098s
# sys 0m0,181s
Source: sum.cpp
Dobry system budowania dostarcza wsparcie dla różnych, nazwanych typów kompilacji.
Systemy Budowania #
C++ nie ma wystandaryzowanego systemu budowania. Różne platformy dostarczają swoje narzędzia:
- GNU Make (Linux)
- MinGW Make (Windows + MinGW)
- NMake (Windows + VisalStudio)
- Ninja
- Visual Studio Solutions
- XCode projects
Do tej pory wykorzystywaliśmy GNU Make.
Projekty wieloplatformowe, których kod jest rozwijany, np. dla platform Windows i Linux potrzebują systemu budowania opisującego projekt w sposób niezależny od platformy. Środowisko programistów stworzyło kilka takich narzędzi, np.:
Każde z nich to zupełnie inne narzędzie wymagające nauki.
Spośród wszystkich wymienionych, CMake można uznać za de-facto standard w zakresie systemu budowania dla języka C++. Ma ogromny (> 50%) udział w rynku. Rozpoczynając pracę w projekcie pisanym w C++ lub tworząc nowy, istnieje duża szansa, że to właśnie CMake będzie systemem budowania.
CMake #
CMake to tzw. meta system budowania (meta build system). To narzędzie, które na podstawie skryptowego opisu projektu generuje właściwy system budowania, odpowiedni dla platformy (np. Unix Makefiles), na którą w danej chwili budujemy oprogramowanie. Ten sam opis może posłużyć do generacji innego systemu budowania, budując projekt w odmiennym środowisku (np. VS Solutions).
CMake to zwykły program, który trzeba zainstalować, najlepiej przy pomocy menadżera pakietów.
Narzędzie cmake odczytuje konfigurację z gównego katalogu projektu, tzw. source directory
i generuje właściwy system budowania w innym katalogu, tzw. build directory, często zagnieżdżonym w źródłach.
Istnieje też możliwość wygenerowania systemu budowania w tym samym katalogu, co źródła, czyli tzw. in-source-build.
To odradzana opcja ze względu na zaśmiecanie katalogu źródłowego plikami tymczasowymi.
Projekt jest opisywany za pomocą tekstowych skryptów konfiguracyjnych CMakeLists.txt. Uruchomienie cmake
zawsze przebiega przez następujące po sobie fazy: configure, generate. Potem zwykle następuje uruchomienie
wygenerowanego systemu budowania, czyli tzw. faza build.
Minimalny projekt składa się z pliku main.cpp i opisu CMakeLists.txt:
cmake_minimum_required(VERSION 3.16)
project(intro VERSION 1.0.0)
add_executable(main main.cpp)
Język opisu projektu to język skryptowy. cmake interpretuje i wykonuje treść pliku CMakeLists.txt linijka po linijce
tak jak powłoka. Narzędzie ma kilka podstawowych sposobów wywołania:
cmake [<options>] <path-to-source-dir> # Wygeneruj system budowania w katalogu roboczym (cwd)
cmake [<options>] <path-to-build-dir> # Re-generuj system budowania obecny we wskazanym katalogu
cmake [<options>] -S <path-to-source-dir> -B <path-to-build-dir> # Jawnie wskazane katalogi źródłowe i docelowe
rm -Rf build && mkdir build && cd build
cmake ../cmake/intro
rm -Rf build
cmake -S cmake/intro -B build
Powyższe wywołania robią to samo: generują buildsystem w katalogu build dla projektu w katalogu cmake/intro.
Warto zwrócić uwagę na wyjście generowane przez program:
-- The C compiler identification is GNU 13.3.0
-- The CXX compiler identification is GNU 13.3.0
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/cc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done (0.2s)
-- Generating done (0.0s)
-- Build files have been written to: /cpp-site/content/wyk/w4/build
Narzędzie wykonało mnóstwo pracy niejawnie:
- odnalazło w systemie kompilator dla języków C i C++ (
gccig++). - sprawdziło, czy kompilatory działają poprawnie (budując mały program generowany w locie)
- przetestowało kompilatory pod względem wspieranych funkcjonalności i interfejsu
- wygenerowało buildsystem w katalogu
build
To wszystko efekt wykonania funkcji project().
Configure #
W pierwszym kroku cmake odczytuje i wykonuje plik CMakeLists.txt z katalogu źródłowego.
Wykonując instrukcje w nim zawarte generuje plik CMakeCache.txt w katalogu wyjściowym wypełniając
go tzw. cache variables. Są zmienne tekstowe, pary klucz-wartość, których wartości są zachowywane
pomiędzy następującymi po sobie wywołaniami cmake. Dzięki zapamiętywaniu re-generacja jest znacznie szybsza.
Przykładowe informacje cache’owane w zmiennych to:
- wykryty kompilator i inne narzędzia do budowania
- rodzaj kompilacji, flagi kompilatora
- opcje specyficzne dla projektu
Wyjście z ponownego uruchomienia jest znacznie krótsze:
cmake -S cmake/intro -B build
-- Configuring done (0.0s)
-- Generating done (0.0s)
-- Build files have been written to:/cpp-site/content/wyk/w4/build
Zawartość cache zwykle nie zmienia się pomiędzy wywołaniami, choć czasami może być to przydatne (np. zmiana rodzaju
kompilacji).
Użytkownik ma możliwość edycji wartości zmiennych w CMakeCache.txt. Może to zrobić ręcznie, przy użyciu cmakegui
lub z poziomu linii zlecenia za pomocą opcji -D <var>:<type>=<value>:
cmake -DCMAKE_BUILD_TYPE:STRING=Release build # Zapisz wartość CMAKE_BUILD_TYPE przed re-konfiguracją
Generate #
Po zakończeniu wykonania skryptu CMakeLists.txt narzędzie natychmiast wykonuje drugi krok: generację natywnego
buildsystemu.
O tym, jaki buildsystem zostatnie wygenerowany (makefile, ninja, VS Solutions, etc.) decyduje wartość zmiennej
CMAKE_GENERATOR w CMakeCache.txt.
Ten krok jest w większości całkowicie automatyczny. Skrypty, które pisze użytkownik są w całości wykonywane wcześniej. Istnieje pewna klasa wyrażeń, tzw. generator expressions, których ewaluacja jest opóźniana aż do kroku generacji.
Build #
Po wygenerowaniu systemu budowania można w końcu go uruchomić i zbudować nasz projekt. Znając jego rodzaj, można to zrobić ręcznie, np.:
cd build
make
Albo lepiej, skorzystać z tego że CMake potrafi wywołać buildsystem:
cmake --build build --target clean
cmake --build build
Większość generowanych systemów budowania na począku sprawdza, czy czasem opis projektu się nie zmienił (
CMakeLists.txt).
Jeśli tak to automatycznie ponownie wykonuje cmake przed krokiem build.
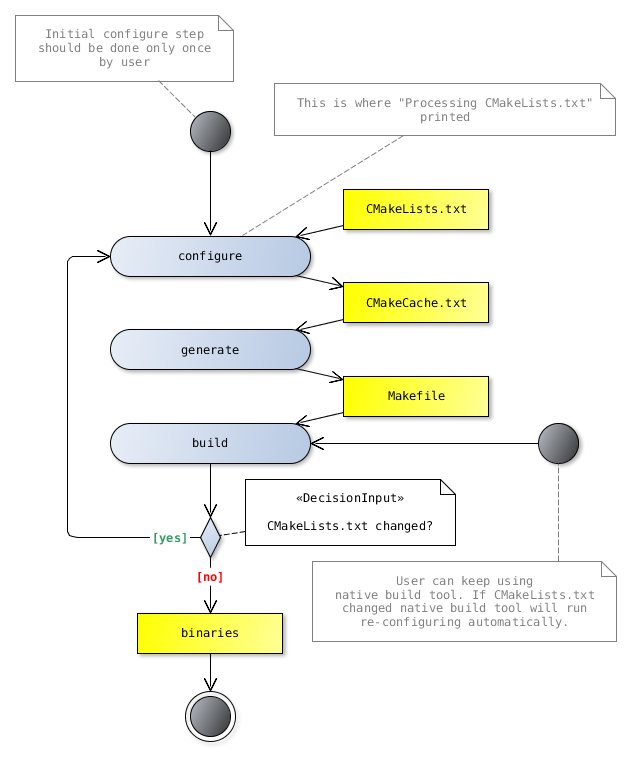
Żródło: CGold 0.1 documentation
Po zmianie czegokolwiek w pliku CMakeLists.txt uruchomienie budowania powoduje re-generację:
cmake --build build
# -- Configuring done (0.0s)
# -- Generating done (0.0s)
# -- Build files have been written to:/cpp-site/content/wyk/w4/build
# [ 50%] Building CXX object CMakeFiles/intro.dir/main.cpp.o
# [100%] Linking CXX executable intro
# [100%] Built target intro
Struktura projektu #
Żródła większych projektów zwykle są podzielone hierarchicznie na podkatalogi reprezentujące różne komponenty systemu.
Skrypt CMakeLists.txt zwykle też jest podzielony na pod-skrypty. Te nie są wykonywane automatycznie,
interpreter nie przegląda automatycznie podkatalogów. Wymagane jest użycie jawne użycie dyrektywy add_subdirectory().
cmake w jej miejscu wykonuje skrypt CMakeLists.txt znaleziony we wskazanym podkatalogu.
Popatrzmy na przykładowy projekt składający się z biblioteki utils, pliku wykonywalnego
main korzystającego z tej biblioteki, oraz pliku wykonywalnego test zawierającego
testy dla biblioteki utils.
.
├── CMakeLists.txt
├── generator
│ ├── CMakeLists.txt
│ ├── generator.cpp
│ └── include
│ └── generator.hpp
├── main
│ ├── CMakeLists.txt
│ └── main.cpp
├── person
│ ├── CMakeLists.txt
│ └── include
│ └── person.hpp
├── test
│ ├── CMakeLists.txt
│ └── test.cpp
└── utils
├── CMakeLists.txt
├── impl.cpp
├── impl.hpp
├── include
│ └── utils.hpp
└── utils.cpp
Sources: View on GitHub
Główny skrypt CMakeLists.txt wykonuje skrypty w podkatalogach, gdzie definiowane są
poszczególne elementy projektu:
cmake_minimum_required(VERSION 3.16)
project(libs VERSION 1.0.0)
add_subdirectory(utils)
add_subdirectory(main)
add_subdirectory(test)
rm -Rf build
cmake -S cmake/libs -B build
Zwykle każda biblioteka i plik wykonywalny są umieszczane w osobnym katalogu źródłowym razem z towarzyszącym opisem.
Targets #
Kluczowym zadaniem skryptów CMakeLists.txt jest zadeklarowanie
budowalnych elementów projektu: bibliotek i plików wykonywalnych.
Służą ku temu dyrektywy add_executable
i add_library:
add_executable(<name> [source1] [source2 ...])
add_library(<name> [STATIC | SHARED | MODULE] [<source>...])
Ścieżki do źródeł są podawane względem katalogu, w którym znajduje aktualnie wykonywany plik CMakeLists.txt.
Biblioteki i programy mają różnorodne **właściwości ** pozwalające sterować procesem ich budowania. Do najważniejszych należą:
INCLUDE_DIRECTORIESkatalogi, w których poszukiwane są pliki nagłówkowe podczas budowania biblioteki/programuINTERFACE_INCLUDE_DIRECTORIES: katalogi, w których poszukiwane są pliki nagłówkowe podczas budowania bibliotek/programów zależnychLINK_LIBRARIES: biblioteki linkowane podczas budowania danej biblioteki/programuINTERFACE_LINK_LIBRARIES: biblioteki linkowane podczas budowania bibliotek/programów zależnychCOMPILE_DEFINITIONS: makrodefinicje ustawiane podczas budowania danej biblioteki/programuINTERFACE_COMPILE_DEFINITIONS: makrodefinicje ustawiane podczas budowania bibliotek/programów zależnych
Poszczególne właściwości są modyfikowane za pomocą dedykowanych procedur.
Include directories #
Biblioteki definiują swój interfejs publiczny za pomocą zbioru plików nagłówkowych położonych w pewnym katalogu.
Konsumenci biblioteki, używający dyrektyw #include "...", muszą móc odnajdywać te pliki nagłówkowe.
Korzystanie ze ścieżek względnych lub bezwzględnych w kodzie źródłowym nie jest dobrym rozwiązaniem.
Konsumenci biblioteki libfoo powinni po prostu pisać #include "foo.hpp" bez względu na to,
gdzie ta biblioteka się fizycznie znajduje. Służą do tego flagi kompilatora takie jak -I<dir>
dodające daną ścieżkę do listy przeszukiwanych katalogów. CMake dostarcza wygodny interfejs to ustawiania tych flag.
add_library(utils utils.cpp impl.cpp)
target_include_directories(utils PUBLIC include)
Komendy kompilacji plików źródłowych biblioteki utils jak i programów, które jej potrzebują
będą posiadały opcję -I/cpp-site/content/wyk/w4/cmake/libs/utils/include pozwalając na poprawne wykonanie
dyrektywy #include "utils.hpp".
cmake --build build -- VERBOSE=1
# ...
# [ 25%] Building CXX object utils/CMakeFiles/utils.dir/utils.cpp.o
# cd /cpp-site/content/wyk/w4/build/utils &&
# /usr/bin/c++
# -I/cpp-site/content/wyk/w4/cmake/libs/utils/include
# -MD -MT utils/CMakeFiles/utils.dir/utils.cpp.o
# -MF CMakeFiles/utils.dir/utils.cpp.o.d
# -o CMakeFiles/utils.dir/utils.cpp.o
# -c /cpp-site/content/wyk/w4/cmake/libs/utils/utils.cpp
# ...
Pełna składnia dyrektywy wygląda następująco:
target_include_directories(<target> [SYSTEM] [AFTER|BEFORE]
<INTERFACE|PUBLIC|PRIVATE> [items1...]
[<INTERFACE|PUBLIC|PRIVATE> [items2...] ...])
Każda grupa katalogów (items...) jest poprzedzona słowem PUBLIC, PRIVATE lub INTERFACE.
Te mówią o tym, do których z dwóch własności *INCLUDE_DIRECTORIES dopisać ścieżki:
INTERFACEdodaje wyłącznie do własnościINTERFACE_INCLUDE_DIRECTORIESPRIVATEdodaje wyłącznie do własnościINCLUDE_DIRECTORIESPUBLICdodaje jednej i drugiej
Ścieżki we własności INCLUDE_DIRECTORIES są uwzględniane wyłącznie podczas kompilacji samej biblioteki.
Jest to więc prywatny detal implementacyjny biblioteki niewpływający na jej konsumentów.
Ścieżki we własności INTERFACE_INCLUDE_DIRECTORIES są uwzględniane podczas kompilacji programów i bibliotek
zależnych. Populując tę własność biblioteka mówi innym gdzie znajdują się jej nagłówki.
Kiedy zatem używać jakiego trybu? Najlepiej podsumuje to tabela:
| Kto potrzebuje? ja/konsumenci | Nie potrzebują | Potrzebują |
|---|---|---|
| Nie potrzebuję | INTERFACE | |
| Potrzebuję | PRIVATE | PUBLIC |
Link libraries #
Zależności między bibliotekami i programami definiujemy linukując elementy do bibliotek.
add_executable(main main.cpp)
target_link_libraries(main PRIVATE generator)
W powyższym przykładzie program main zależy od biblioteki generator.
- biblioteka
generatormusi być zbudowana jako pierwsza; - podczas linkowania programu
mainzostanie włączona bibliotekagenerator; - własności
INTERFACE_*bibliotekigenerator, takie jakINTERFACE_INCLUDE_DIRECTORIESbędą uwzględnione podczas budowania programumain.
Dla naszego projektu graf zależności wygląda następująco:
graph LR
main -.->|PRIVATE| generator
generator -.->|PRIVATE| utils
generator -->|PUBLIC| person
test -.->|PRIVATE| utilsDyrektywa target_link_libraries() ma podobną składnię do target_include_directories():
target_link_libraries(<target>
<PRIVATE|PUBLIC|INTERFACE> <item>...
[<PRIVATE|PUBLIC|INTERFACE> <item>...]...)
Znaczenie słów PRIVATE, PUBLIC, INTERFACE jest analogiczne:
PRIVATEjeżeli to ja potrzebuję biblioteki, a moi konsumenci niePUBLICjeżeli zarówno ja, jak i moi konsumenci potrzebują danej biblioteki do budowaniaINTERFACEjeżeli tylko moi konsumenci powinni linkować bibliotekę, ja nie muszę
Słowa te wpływają na to, które z własności LINK_LIBRARIES i INTERFACE_LINK_LIBRARIES zostaną rozbudowane.
Biblioteka, która w swoich publicznych nagłówkach zawiera dyrektywy
#include ""załączająca nagłówki jej zależności, musi deklarować tę zależność jako PUBLIC!
GDB #
Podstawowym narzędziem do diagnozowania błędów w oprogramowaniu podczas jego tworzenia (i nie tylko) jest debugger. To program, który pozwala kontrolować wykonanie innego programu, poruszać się po instrukcjach krokowo lub skokowo w trakcie jego wykonania, podglądać i interaktywnie modyfikować stan programu, zmiennych, pamięci.
gdb jest takim właśnie debuggerem. Dostarcza potężny interfejs tekstowy, wymagający nauki do uzyskania biegłości,
ale praktycznie każde środowisko programistyczne da się z nim zintegrować, udostępniając interfejs graficzny.
Symbole debugera #
Debugger zwykle potrzebuje do pracy dodatkowych informacji opisujących wykonywany kod binarny. To tzw. symbole debugera opisujące zmienne, funkcje, konkretne linijki kodu, pozwalą tłumaczyć adres wykonywanej instrukcji lub adres zmiennej na ich umiejscowienie w kodzie źródłowym. Bez tych informacji wyjście debugera będzie nieczytelne.
Kompilator generuje te informacje w procesie translacji i może je opcjonalnie umieścić w pliku wynikowym.
Przykładowo, w gcc i clang służy do tego przełącznik -g. Niektóre kompilatory umieszczają symbole w osobnym pliku.
g++ gdb/main.cpp -o main.out && ll -h main.out
g++ -g gdb/main.cpp -o main.out && ll -h main.out
file main.out
Source: main.cpp
Symbole można wydzielić do osobnego pliku za pomocą narzędzia objcopy:
objcopy --only-keep-debug main.out main.debug
strip -g main.out
file main.out
Uruchamianie #
Skompilowany plik wykonywalny można uruchomić pod nadzorem gdb
przekazując ścieżkę do pliku binarnego:
gdb ./main.out
# Reading symbols from ./main.out...
Nie przekazujemy tutaj argumentów programu. Nasz program jeszcze się nie wykonuje!
gdb interpretuje polecenia wprowadzane na standardowe wejście sterujące
procesem debugowania. Pierwszym poleceniem będzie run: uruchom program.
(gdb) run
Starting program: /cpp-site/content/wyk/w4/main.out
Filling list with dummy data ...
-1 0 1 2 2 3
-1 0 1 3
[Inferior 1 (process 14134) exited normally]
Program wykonał się i zakończył poprawnie.
Do polecenia run można przekazać argumenty programu:
(gdb) run 1 2 3
Starting program: /cpp-site/content/wyk/w4/main.out 1 2 3
Reading list from argv[]
1 2 3
1 3
[Inferior 1 (process 14247) exited normally]
Plik wykonywalny można też wskazać już po uruchomieniu gdb:
gdb
(gdb) file ./main.out
Reading symbols from ./main.out...
Można też podłączyć gdb do działającego procesu znając jego numer.
gdb ./main.out 14247
Breakpoints #
Domyślnie program wykonuje się bez zatrzymania aż do końca (lub błędu). Chcąc obserwować zachowanie programu krok po kroku trzeba wstrzymać jego wykonanie. Służy do tego tzw. breakpoint, czyli oznaczone miejsce w programie, po którego osiągnięciu
Breakpointy definiujemy poleceniem break podając nazwę funkcji,
numer linii w kodzie lub nawet adres pojedynczej instrukcji.
(gdb) break main.cpp:87
(gdb) break SortedLinkedList::remove
(gdb) info break
Num Type Disp Enb Address What
1 breakpoint keep y 0x00005555555565a6 in main(int, char**) at gdb/main.cpp:87
2 breakpoint keep y 0x0000555555556971 in SortedLinkedList::remove(int) at gdb/main.cpp:48
(gdb) run
Breakpoint 1, main (argc=1, argv=0x7fffffffdb18) at gdb/main.cpp:87
87 list.print();
Wykonanie programu zostało wstrzymane przed wejściem do metody list.print().
Polecenia where i list pokażą obecne miejsce w programie:
(gdb) where
#0 main (argc=1, argv=0x7fffffffdb18) at gdb/main.cpp:87
(gdb) list
82 {
83 list.insert(std::stoi(argv[i]));
84 }
85 }
86
87 list.print();
88 list.remove(2);
89 list.print();
90 return 0;
91 }
Nawigacja #
Do sterowania krokowym wykonaniem programu po osiągnięciu breakpointa służą 3 polecenia:
next: przejdź do następnej linii kodustep: przejdź do następnej instrukcji (wchodząc do funkcji)finish: wyjdź z obecnej funkcji
Istotna jest różnica między next i step. next przeskoczy przez wszystkie wywołania funkcji, metod, konstruktorów,
w bieżącej linii. step będzie do nich wchodzi po kolei.
Polecenie continue wznawia wykonanie programu aż do osiągnięcia następnego breakpointa.
Pamięć #
gdb ma dostęp do całej pamięci programu w trakcie wykonania. Może ją odczytywać i modyfikować!
Po wstrzymaniu wykonywania programu możemy np. wydrukować wartości zmiennych lub je ustawić za pomocą poleceń:
printewaluuje wartość wyrażenia i je wyświetlaset variableustawia wartość zmiennej
(gdb) break fill
(gdb) run
Breakpoint 1.1, fill (list=..., v=std::vector of length 6, capacity 6 = {...}) at gdb/main.cpp:61
61 for (std::size_t i = 0; i < v.size(); ++i)
(gdb) next
63 list.insert(v[i]);
(gdb) print i
$6 = 0
(gdb) set variable i = 100000000
(gdb) next
Program received signal SIGSEGV, Segmentation fault.
Coredumps #
Czasami interaktywne debugowanie aplikacji nie jest możliwe. Program w momencie wystąpienia błędu może być uruchomiony na produkcyjnej maszynie, do której programista nie ma bezpośredniego dostępu.
g++ -g gdb/core.cpp -o core.out
./core.out hi my friend
# Segmentation fault (core dumped)
Source: core.cpp
Program zakończył się z błędem. Otrzymaliśmy komunikat Segmentation fault (core dumped) - co to oznacza? Segmentation fault to typ błędu, program dokonał niepoprawnego odwołania do pamięci i został zabity przez system operacyjny. Informacja core dumped oznacza, że system przed zamknięciem aplikacji zrzucił stan programu (całą jego pamięć) do pliku celem dalszej diagnozy. Taki plik to właśnie coredump, który można później załadować w debugerze i obejrzeć stan programu w momencie awarii.
Ciężko określić gdzie znaleźć pliki generowane przez system automatycznie w momencie awarii. To proces zależny od dystrybucji i konfiguracji systemu. Na niektórych systemach domyślne ten proces jest wyłączony. Na niektórych plik zostanie wygenerowany w katalogu z programem, na niektórych w jakimś katalogu systemowym. Należy to sprawdzić w dokumentacji konkretnego systemu.
Przykładowo, na Ubuntu, po zainstalowaniu pakietu systemd-coredump wygląda to tak:
coredumpctl list # wyświetl listę zrzutów
# TIME PID UID GID SIG COREFILE EXE SIZE
# Sun 2025-04-06 15:51:43 CEST 25667 1000 1000 SIGSEGV present /cpp-site/content/wyk/w4/core.out 2.4M
# Sun 2025-04-06 16:10:02 CEST 30119 1000 1000 SIGSEGV present /cpp-site/content/wyk/w4/core.out 2.4M
coredumpctl dump --output my.core # zapisz ostatni zrzut do pliku my.core
ll -h
# -rw-rw-r-- 1 user user 6,3M kwi 6 16:11 my.core
Poleceniem gcore można również wymusić zrzut pamięci działającego procesu, podając jego
identyfikator. Uruchamiając program w jednym terminalu:
./core.out
hi
alex
Odszukajmy jego PID i użyjmy polecenia gcore:
ps -a
# 26369 pts/3 00:00:00 core.out
# 26859 pts/4 00:00:00 ps
gcore 26369
0x000073bf4831ba61 in read () from /lib/x86_64-linux-gnu/libc.so.6
Saved corefile core.26369
[Inferior 1 (process 26369) detached]
W praktyce polecenie podłącza się za pomocą gdb do programu, zatrzymuje jego wykonanie,
dokonuje zrzutu pamięci i się odłącza.
W efekcie otrzymamy na dysku plik, typowo o nazwie core.<pid>:
ll -h
-rw-rw-r-- 1 user user 1,4M kwi 6 15:56 core.26369
-rwxrwxr-x 1 user user 123K kwi 6 15:51 core.out*
Plik można załadować do gdb podając go jako dodatkowy argument lub używając polecenia
core-file:
gdb core.out # alternatywnie gdb core.out my.core
(gdb) core-file my.core
# Core was generated by `./core.out'.
# Program terminated with signal SIGSEGV, Segmentation fault.
# #0 0x00007347b2f68d14 in std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::size() const () from /lib/x86_64-linux-gnu/libstdc++.so.6
Nie można wykonywać dalej takiego programu, można tylko oglądać jego stan w momencie zrzutu. Przydatne podczas diagnostyki mogą być tutaj polecenia:
backtrace: wydruk stosu wywołańup/down: nawigacja w dół/górę po ramkach stosu
(gdb) bt
#0 0x00007347b2f68d14 in std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::size() const () from /lib/x86_64-linux-gnu/libstdc++.so.6
#1 0x0000590a8047a8d1 in std::operator==<char, std::char_traits<char>, std::allocator<char> > (__lhs=<error reading variable: Cannot access memory at address 0x8>, __rhs="hello") at /usr/include/c++/13/bits/basic_string.h:3714
#2 0x0000590a8047a4b0 in std::operator!=<char, std::char_traits<char>, std::allocator<char> > (__lhs=<error reading variable: Cannot access memory at address 0x8>, __rhs="hello") at /usr/include/c++/13/bits/basic_string.h:3791
#3 0x0000590a8047994d in find (head=0x0, text="hello") at gdb/core.cpp:58
#4 0x0000590a80479ab3 in main (argc=1, argv=0x7fff60835058) at gdb/core.cpp:83
(gdb) up 3
#3 0x0000590a8047994d in find (head=0x0, text="hello") at gdb/core.cpp:58
58 while (head->text != text)
Widzimy, że crash nastąpił w momencie wykonania funkcji size() obiektu typu std::string.
Wywołanie tej metody pochodzi z instrukcji head->text != text z wartością head = 0x0. Czyli typowy
null pointer dereference.
Sanitizers #
Poza znanym już Address Sanitizerem kompilatory dostarczają inne narzędzia wykrywające inne klasy błędów. Nie wszystkie można ze sobą łączyć.
Leak Sanitizer (LSan) #
LSan wykrywa wycieki pamięci, monitorując wszystkie alokacje i dealokacje.
g++ -g -fsanitize=leak lsan.cpp -o lsan.out
./lsan.out
# =================================================================
# ==41099==ERROR: LeakSanitizer: detected memory leaks
#
# Direct leak of 3 byte(s) in 3 object(s) allocated from:
# #0 0x7b7705616222 in operator new(unsigned long) ../../../../src/libsanitizer/lsan/lsan_interceptors.cpp:248
# #1 0x5ded302fa1f9 in main /cpp-site/content/wyk/w4/lsan.cpp:12
# #2 0x7b7704e2a1c9 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
# #3 0x7b7704e2a28a in __libc_start_main_impl ../csu/libc-start.c:360
# #4 0x5ded302fa0e4 in _start (/cpp-site/content/wyk/w4/lsan.out+0x10e4) (BuildId: c391bc698ad8a7fa4075a0046f4f1e37d4770943)
#
# SUMMARY: LeakSanitizer: 3 byte(s) leaked in 3 allocation(s).
Source: lsan.cpp
Undefined Behavior Sanitizer (UBSan) #
UBsan wykrywa liczne, różnorodne błędy t.j. dereferencje niepoprawnych wskaźników, dzielenie przez 0, przepełnienia podczas rzutowań i innych operacji arytmetycznych. Dodaje sprawdzenia przez każdą instrukcją mogącą wywołać niezdefiniowane zachowanie.
g++ -g -fsanitize=undefined ubsan.cpp -o ubsan.out
./ubsan.out
# ubsan.cpp:5:7: runtime error: signed integer overflow: 2147483647 + 1 cannot be represented in type 'int'
Source: ubsan.cpp
Stack Protector #
Opcja -fstack-protector włącza mechanizm chroniący przed przepełnieniami stosu.
Kompilator umieszcza dodatkową wartość na stosie, za wszystkimi zmiennymi lokalnymi
i dodaje sprawdzenia jej wartości przy wyjściu z funkcji. Kończy program, jeżeli wykryje
jej nadpisanie.
g++ -g -fstack-protector stack-protector.cpp -o stack-protector.out
./stack-protector.out
# 2 + 3 = 5
./stack-protector.out
# 2 asdfasdfasdf 4
# *** stack smashing detected ***: terminated
Zależności #
Podobnie jak w przypadku buildsystemu, C++ nie posiada standardowego menadżera zależności projektu. Zależność od zewnętrznej biblioteki jest tym samym ciężka do zdefiniowania w sposób przenośny i zrozumiały dla innych programistów.
Weźmy jako przykład użycie popularnej małej biblioteki do formatowania tekstu libfmt w naszym programie:
#include <fmt/core.h>
int main() {
fmt::print("Hello, world!\n");
}
Source: View on GitHub .
Budując ten projekt najpewniej dostaniemy błąd podczas analizy dyrektywy #include:
cmake -S deps -B deps/build
cmake --build deps/build
# /cpp-site/content/wyk/w4/deps/src/main.cpp:1:10: fatal error: fmt/core.h: No such file or directory
# 1 | #include <fmt/core.h>
# | ^~~~~~~~~~~~
Biblioteka fmt musi być dostępna dla linkera, żeby ten poprawnie zastosował flagę -lfmt.
Skąd wziąć tą bibliotekę? Gdzie ją umieścić? Jest wiele opcji.
Systemowy menadżer pakietów #
sudo apt install libfmt-dev
cmake --build build
W systemie buudowania należy przekazać odpowiednią flagę linkera:
target_link_libraries(main PRIVATE fmt)
Wady:
- Możemy nie mieć uprawnień do instalowania
- Na etapie konfiguracji projektu buildsystem
cmakenie jest w stane stwierdzić czy biblioteka istnieje, czy nie - Trzeba dokumentować, np. w pliku
README.md, co trzeba zainstalować, zanim zaczniemy pracować z projektem - Programiści rozwijający ten sam projekt na różnych maszynach z różnymi systemami mogą zainstalować bibliotekę w różnych wersjach
sudo apt remove libfmt-dev
Budowanie ręczne #
Można oczywiście pobrać źródła, zbudować, zainstalować w jakimś katalogu, który wskażemy systemowi budowania.
git clone https://github.com/fmtlib/fmt fmt
cmake -S fmt -B fmt/build -DCMAKE_INSTALL_PREFIX=$(pwd)/libs/fmt/
cmake --build fmt/build --parallel 8
cmake --build fmt/build --target install
cmake -S deps -B deps/build -DCMAKE_PREFIX_PATH=$(pwd)/libs/fmt/
cmake --build deps/build
Wady:
- Budowanie zależności może trwać bardzo długo
- Każdy programista musi wykonać ręcznie dużo kroków, zanim zacznie pracować z właściwym projektem
- Aktualizacja biblioteki również musi być ręcznie wykonana i nadzorowana
Włączenie źródeł #
Można pobrać źródła i włączyć je do własnego projektu.
git clone https://github.com/fmtlib/fmt deps/libs/fmt
cmake -S deps -B deps/build
Wady:
- Budowanie zależności może trwać bardzo długo
- Trzeba ręcznie klonować przed rozpoczęciem pracy
- Aktualizacja biblioteki również musi być ręcznie wykonana i nadzorowana
- Sama zależność musi mieć kompatybilny system budowania (cmake)
Pobranie źródeł podczas konfiguracji #
cmake może pobierać źródła w trakcie konfiguracji projektu.
include(FetchContent)
FetchContent_Declare(
fmt
GIT_REPOSITORY https://github.com/fmtlib/fmt.git
GIT_TAG 10.1.1 # Use the specific version you want (e.g., latest stable tag)
)
FetchContent_MakeAvailable(fmt)
Moduł CMake FetchContent pozwala pobierać zawartość repozytorium i budować ją w trakcie kroku configure.
Wady:
- Budowanie zależności może trwać bardzo długo
- Sama zależność musi mieć kompatybilny system budowania (cmake)
Podobnym rozwiązaniem byłoby użycie funkcjonalności git: git submodule (dla chętnych).
Dedykowany menadżer pakietów #
Jednym z dostępnych narzędzi jest vcpkg. Trzeba go zainstalować:
git clone https://github.com/microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh # Linux/macOS
Potem można z niego korzystać podobnie do menadżera systemowego:
./vcpkg search fmt
# fmt 11.0.2#1 {fmt} is an open-source formatting library providing a fast and safe alter...
./vcpkg install fmt
Systemowi budowania trzeba wskazać, że ma korzystać z pakietów zainstalowanych w vcpkg:
rm -Rf deps/build
cmake -S deps -B deps/build -DCMAKE_TOOLCHAIN_FILE=/home/saqq/vcpkg/scripts/buildsystems/vcpkg.cmake
cmake --build deps/build
Wady:
- Nowe narzędzie, często skomplikowane
- Trzeba ręcznie dokumentować jakie zależności należy zainstalować
Podobnym, równie popularnym rozwiązaniem jest conan.
Testowanie #
Oprogramowanie trzeba testować. Testowanie polega na uruchamianiu naszego kodu lub jego części i sprawdzaniu jego odpowiedzi na określone wejście. Testy automatyczne to programy, które uruchamiają pojedyncze funkcje, moduły, komponenty, aż do całego rozwiązania, symulują wejście, oczekują określonego wyjścia.
Można robić to ręcznie tak jak w przykładowym projekcie CMake:
static int test_counter = 1;
void run_test(void (*fn)()) {
std::cout << "Test no. " << test_counter++ << ": ";
fn();
std::cout << "OK" << std::endl;
}
void test_random_name_not_empty() {
std::string name = utils::random_name();
assert(name.size() > 0);
}
void test_random_name_starts_uppercase() {
std::string name = utils::random_name();
assert(name[0] >= 'A' && name[0] <= 'Z');
}
int main() {
std::srand(std::time(nullptr));
run_test(test_random_name_not_empty);
run_test(test_random_name_starts_uppercase);
return 0;
}
Source: test.cpp
Nietrudno zauważyć, że ten mikro-framework składający się z funkcji run_test jest dość ubogi.
Istnieje wiele bibliotek ułatwiających zadanie programistom C++:
GoogleTest #
Najpopularniejszą jest pierwsza: GTest. Warto ją znać i wykorzystywać do testowania swojego kodu.
Dokumentacja jest dostępna pod adresem: https://google.github.io/googletest/primer.html
Biblioteka dostarcza funkcje do definiowania i wykonywania testów, generując czytelne raporty.
Rozważmy przykładowy projekt złożony z biblioteki functions i pliku wykonywalnego main:
View on GitHub
.
cmake -S testing -B testing/build
cmake --build testing/build
./testing/build/test/fn_test
Projekt pobiera bibliotekę GTest za pomocą mechanizmu FetchContent i
dostarcza kilka przykładowych testów w katalogu test/.
Pojedyncze testy w GTest definiuje się za pomocą makra TEST(TestSuite, TestName):
TEST(HelloTest, BasicAssertions) {
EXPECT_STRNE("hello", "world");
EXPECT_EQ(7 * 6, 42);
}
Test jest funkcją, jej ciało następuje w bloku { ... } po makrze TEST.
Można tam wstawić dowolny kod.
GTest dostarcza potężny zestaw makr ASSERT_ i
EXPECT_, których używamy do sprawdzenia poprawności zachowania testowanego kodu. ASSERT_ w przeciwieństwie
do EXPECT_ przerywa działanie testu w przypadku niepoprawności.
Zwykły test nie ma parametrów, musi wszystko przygotować w ciele. Często zestaw testów współdzieli dane, zależności, które trzeba przygotować przed właściwym testem. Kończyłoby się to dużą duplikacją.
GTest pozwala definiować klasy (tzw. fixtury), które zawierają dane i kod przygotowujący do wykonania testu. Pola klasy są dostępne z poziomu ciała testu.
class MyTestSuite : public ::testing::Test {
protected:
std::vector vals;
MyTestSuite() {} // #1
void SetUp() { vals = {1, 2, 3} } // #2
void TearDown() {} // #4
~MyTestSuite(); // #5
};
TEST_F(MyTestSuite, MyTest1) {
EXPECT_EQ(vals.size(), 3); // #3
}
TEST_F(MyTestSuite, MyTest2) {
EXPECT_EQ(vals[0], 1); // #3
}
GTest przed każdym testem oznaczonym jako TEST_F powołuje do życia obiekt fixtury (wywołując konstruktor),
uruchamia metodę SetUp(), potem wykonuje test, następnie wywołuje metodę TearDown() i niszczy obiekt fixtury.
Ten proces dzieje się dla każdego testu osobno.
Przykład użycia w string_test.cpp.